

Ce dernier est parti d'un constat simple: il n'existe rien sur le marché qui offre et répond aux attentes et besoins de Google. Il fallait donc développer un truc sur mesure pour les besoins internes transparent, suffisament souple et customizable mais d'une trés grande performance et résilience. Cette fois-ci, ce développement n'est pas destiné à une quelconque commercialisation, directe ou indirecte. A regarder de plus près, les exigences de Google sont incroyables: agréger des milliers de machines, gérer plusieurs Po de stockage, utiliser des machines les plus courantes et standards possibles d'où la nécessité d'augmenter la résistance à la panne de cet environnement, permettre un débit important en lecture et écriture et offrir une capacité de traitement "évolutive", tout ça pour un prix élémentaire du Go/s trés faible. L'avantage certain de Google est de posséder l'ensemble des élements c'est-à-dire de maîtriser parfaitement les applications, ce sont les leurs, et l'OS, l'ouverture de Linux est là pour ça.
Le résultat est là, ça marche sinon on le saurait et on s'en rendrait vite compte. Aujourd'hui, il existe plus de 50 clusters GFS sur la planète, chaque GFS est constitué de plus de 1000 machines serveurs pour une surface disque supérieure au Po, connectées à des pools de 1000 clients, permettant un débit en lecture écriture de plus de 10Go/s en présence de pannes matérielles.
L'esprit est donc de partir de système le plus standard possible et le moins cher et de coupler un grand nombre de machines entre elles pour délivrer le niveau de performance et de disponibilité souhaité, de toutes les façons le plus petit défi de Google ne peut être, dans un temps raisonnable, traité par une simple machine.
 Regarder la configuration "étudiante" en 1997,
Regarder la configuration "étudiante" en 1997, celle juste 3 ans aprés, une révolution est passée par là ou la dernière actuellement en place à Mountain View.
celle juste 3 ans aprés, une révolution est passée par là ou la dernière actuellement en place à Mountain View. Google possède en effet la plus importante capacité de calcul du monde, cela ne signifie plus le plus gros ordinateur car ce temps-là est révolu même les grands centres scientifiques n'en achétent plus, le CEA peut en témoigner, comme Sandia Labs, Lawrence Livermore ou la NASA, leur coût est prohibitif ayant fait les beaux jours de Cray, Thinking Machines ou Convex.
Google possède en effet la plus importante capacité de calcul du monde, cela ne signifie plus le plus gros ordinateur car ce temps-là est révolu même les grands centres scientifiques n'en achétent plus, le CEA peut en témoigner, comme Sandia Labs, Lawrence Livermore ou la NASA, leur coût est prohibitif ayant fait les beaux jours de Cray, Thinking Machines ou Convex.Google est parti d'un constat simple qui tient compte de la nature distribuée d'Internet, de la volonté de répartir les traitements et de cloner des entités entières - leurs clusters par exemple - de répondre aux millions de requêtes par seconde sur le moteur de recherche et surtout de ne pas consacrer une fortune à cette couche, certes critique, mais sans modèle économique immédiat, visible ou direct. N'oublions pas que Google n'utilise que des PCs standards, peut-être certains gonflés, mais de vraies machines "jetables", des consommables finalement, avec tous les aspects universels associés: Linux, Ethernet, IP, SCSI... et peu onéreux, et bien sûr tout ce qui est gratuit, qu'il enrichisse et complète à leur sauce... On compte au moins 450000 machines organisées en cluster installées sur plusieurs sites et zones géographiques, le plus gros en Europe est en Irlande. Pour la petite histoire, Google stocke des dizaines d'exemplaires du Web !!! alors, quand ils indiquent avoir indexé 9 milliards de pages, je vous laisse estimer, pas simple calcul, l'espace nécessaire. Ils ont bien trouvé leur nom: Google c'est un 1 suivi de 100 zéros.
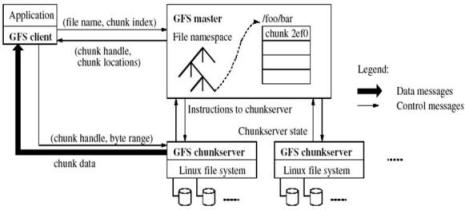
Alors comment ça marche ? simple et compliqué à la fois. Une philosophie asymmétrique a été retenue avec un serveur maître - le GFS Master - protégé par une série de Replicas, qui contrôle plusieurs centaines de serveurs de stockage - les Chunkservers - à la merci des requêtes des machines clientes. L'diée est donc de découper les fichiers en morceau de 64Mo et de répartir les segments élémentaires sur les différents chunkservers le tout en ajoutant la redondance nécessaire. Quand un client souhaite accéder à un fichier, un requête est envoyé au GFS master qui retourne l'identification du chunkserver - un entier sur 64 bits - possédant la donnée ainsi que sa position sur ce serveur et dans le fichier élémentaire. En fait, chaque élément de fichier stocké sur un serveur de stockage est lui-même un fichier dans l'arborescence locale, on a ainsi des fichiers de fichiers et le RAID est effectué entre serveurs et pas seulement entre disques "derrière" chaque serveur. Un chunk est présent au moins 3 fois dans un cluster. La figure ci-dessous illustre la configuration simplifiée d'un cluster GFS. Ouf, c'est quand même pas trivial leur truc, c'est Google... et ce n'est pas fini à voir ce qu'ils préparent.


















0 commentaires:
Post a Comment