

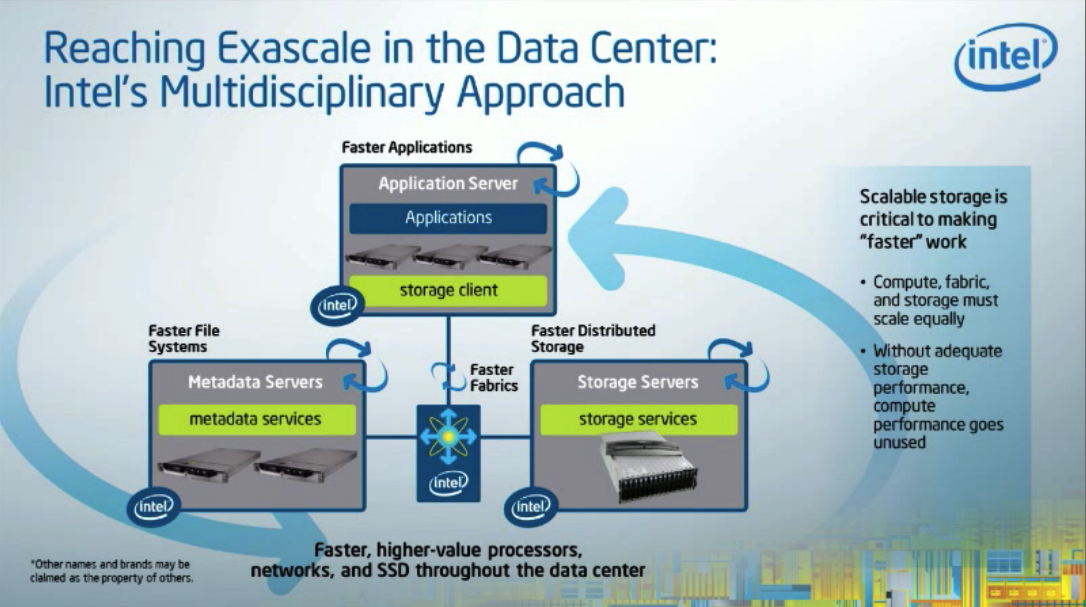
Plus globalement, Intel veut compter dans les grandes infrastructures ExaScale qui sont représentées par les 3 grands domaines: HPC, Big Data et Cloud, voilà son ambition et ces infra sont toutes à base d'Open Source.
Si vous en doutez, regardez les grands d'Internet ou du calcul scientifique. C'est aussi confirmer par les acquisitions des offres de connectivité de QLogic et Cray. Le petit tableau suivant illustre parfaitement la stratégie d'Intel:

Je pense qu'Intel va acquérir Amplidata et placer la technologie Amplidata en Open Source. Cela veut dire qu'OpenStack, Ceph et les autres pourront en profiter. Ce n'est pas fait car le différent entre Cleversafe et Amplidata n'est pas résolu et à la clef plusieurs millions de $ à compenser à Cleversafe, Amplidata a donc un passif qu'Intel devra intégrer. Quand nous assistons à la présentation Intel lors du dernier Next Generation Object Storage Summit la semaine dernière à SF, on comprend certaines choses. Elle s'est déroulée quelques jours près la conférence Intel au sujet du HPC où Intel a annoncé l'Intel Enterprise Edition for Lustre Software. Et puis quelque chose que nous oublions peut-être est la convergence des 3 axes ci-dessus avec un usage d'une technologie d'un segment dans un autre. Intel a bien montré Hadoop sur Lustre il y a quelques temps confirmé par l'annonce récente d'Intel, on imagine alors la technologie Erasure Coding boostée par les chips Intel dans les environnements HPC et Hadoop. Cela confirme aussi cette grande vague de convergence d'architecture sur le marché. Côté Stockage Objet, Intel complète son approche et martèle 4 axes:
- Optimisation des plateformes de stockage object avec des architectures de références. Celle montré était une architecture à base Amplidata.
- Accélération des traitements proposés par la plateforme avec la librairie ISAL (Intelligent Storage Accelerator Lib.) et CAS (Cache Acceleration SW), étonnant comme acronyme puisqu'il fait référence au CAS historique c'est-à-dire au stockage adressable par contenu.
- Un outil de benchmark COSBench qui aujourd'hui supporte les profils: Swift, Amplidata et CDMI.
- et la volonté de supporter l'écosystème Open Source grandissant: Swift avec un blueprint Erasure Coding et des contributions OpenStack.
On verra dans les jours ou semaines qui viennent si cela se confirme, pour ma part j'en suis convaincu, Intel va acquérir Amplidata 1 an après Whamcloud.

















0 commentaires:
Post a Comment