, acronym of Distributed Asynchronous Object Storage, is today an open source project supported by the DAOS Foundation. It powers some of the largest storage clusters on the planet. I invited Johann Lombardi, TSC chair of the foundation, during the recent
in London to learn more about the project and fix a few fuzzy comments and articles I see published on a few places.
Historically this large scale storage software and architecture has been initiated by Intel with the acquisition of Whamcloud in 2012. Intel asked Brent Gorda to lead that activity, he was the past CEO of Whamcloud. This move occurred after SUN acquisitions of CFS - Cluster File Systems - in September 2007 and ClusterStor by Xyratex in November 2010.
At that time, Intel had big storage ambitions with HPC, Big Data and Cloud flavors and some of you probably remembers the simple table, see below, I built in 2013 with several Intel's initiatives and investments in Cloudian, Amplidata, Maxta or Inktank in addition to Hadoop and Whamcloud moves.
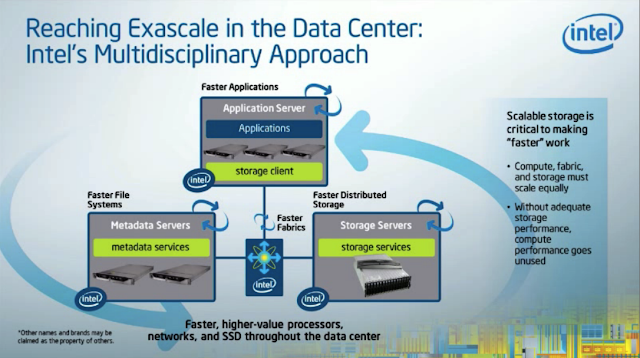
Speaking about HPC and ExaScale, the below Intel picture also summarized pretty well the model at that time, it was circa mid 2013.
These elements are obviously linked to key people, execution and markets reality. And Whamcloud was later swallowed by DDN, it was in 2018.
In 2020, Intel surprised the market, at least part of it, and announced a joint-venture with SK Hynix for its NAND and SSD business to finally create Solidigm. Under the terms of this agreement, SK Hynix paid $7 billion and later $2 billion. Intel finally left this business, the market reality is that Flash and SSD business is controlled by Asian companies and US completely failed, Europe is absent by far as well.
The result of these various events culminated to the creation in 2023 of The DAOS Foundation, a new independent entity established to steward the ongoing development of DAOS as an open source project. This entity oversees governance, funding, and community building, ensuring DAOS remains vendor-neutral and sustainably developed. The founding members are Argonne National Laboratory, Google, HPE and Intel and Vdura, formerly Panasas, joined the organization.
Targeting high-end configurations with exascale requirements especially in terns of IO performance, DAOS implements some specific design choices. First, to clarify things, DAOS is not a file system, I read several times this, it is rather a storage software infrastructure that can be exposed and consumed by diverses interfaces, APIs and more globally access methods. But it implements some parallel mechanisms to boost performance as serialization is the enemy of performance. Among them, I wish to insist on IO operations that make design complex, adding latency that impacts the initial goal and mission of the platform. The teams has chosen to avoid read-modify-write operations, complex and increasing response time. It has been decided to pick a versioning model with a MVCC (multi-version concurrency control) to eliminate locking. Central metadata servers and global objet tables have been also removed to maximize scalability. As a horizontal model, DAOS works as a tight collaboration mode between server, in fact storage servers, and client layers with high numbers in mind, we speak here about thousands of nodes. On the server side, a DAOS engine runs connected with clients via specific user-space libraries such as libdfs and libdaos.
Targeting high performance needs for research centers but also enterprise at large scale, DAOS offers a variety of interfaces with POSIX, NVMe-oF (block), MPI-IO, S3 and Hadoop. In addition, features like multi-tenancy, storage pools to segment data, key to share large configurations plus typed datasets.
Data is protected via replication and erasure coding delivering a high durability level and therefore resiliency. Erasure coding has the beauty to combine striping and redundancy without multi copies of data as only 1 copy is maintained coupled with redundant chunks, fragments or segments depending of the terminology used.
DAOS has demonstrated its performance level being adopted by some of the largest and fastest supercomputers on the planet. This is illustrated by the IO500 benchmark list and the Aurora system, ranked #1, deployed at Argonne National Laboratory.
The foundation plans to announce and release the 2.8 version during SC25 organized in November in St Louis, MI. In the meantime, DAOS will be present at ISC in Hambourg mid June as several vendors will exhibit there. So more news soon.